
RASP的绕过
古早的 RASP 主要是通过两种思路绕过
一种是根据 Runtime.exec() 方法,底层是 ProcessBuilder 再底层 ProcessImpl 更底层的 forkandexec 方法在早两年前是很有效的绕过思路,当时的 RASP 产品并没有 hook native 方法,现在一些高级的 RASP 已经可以 hook native 方法了,JNI 绕过和 forkandexec** **方法绕过就都不太行了
另一种则是开启一个线程来执行命令,让 RASP 失去上下文堆栈的分析数据,使得算法失效, JRASP 提供了解决思路,通过 java.lang.InheritableThreadLocal类在父线程创建子线程时,向子线程传递变量
简单来说就是两种思路:
- 绕过黑名单
- 利用更底层的技术进行绕过
按照这两种思路,我们可以延申出许多绕过 RASP 的方法
JNI/JNA
RASP 工作在 JVM 字节码层面,他能 hook 的也只有 java 相关的方法,那如果我们跳出 JVM,RASP 也会失效
JNI
利用思路很简单就是利用 c 语言生成 dll 文件,然后利用 System.loadLibrar 来加载执行就行了
写一个命令执行的 java 类:
1 | package org.example; |
然后利用 javac 生成 .h 文件
1 | javac -cp . .\Command.java -h org.example.Command |
然后编写对应 c 代码
1 | #include "org_example_Command.h" |
执行下面命令将其编写成 dll 文件
1 | gcc -I "D:\environment\java\jdk-11\include" -I "D:\environment\java\jdk-11\include\win32" -shared -o cmd.dll .\Command.c |
最后编写一个 java 类加载 dll 文件进行命令执行
这样执行命令的时候就不是执行 Runtime 等方法了,绕过了 RASP
JNA
JNA 则更加简单易用
首先,需要目标应用环境中存在 jna.jar 包
1 | import com.sun.jna.Library; |
FFM API
在 JDK21 引入了Foreign Function & Memory API(JEP 442,Third Preview),设计初衷是替代 JNI,为 Java 提供高性能本地互操作能力,这套 API 开辟了一条不经过传统 Java API 层的原生代码执行通道——通过 FFM API 直接调用 glibc 的 system() 函数,整个路径不经过 Runtime 或 ProcessBuilder
更进一步可以利用 mmap() 分配有执行权限的内存区域并加载 shellcode,可以在 JVM 进程空间直接执行机器码,不产生任何子进程
调用流程
FFM API 调用一个本地函数分四步
- 获取 Linker
Linker 是 java 与本地代码的桥梁,提供 downcall(Java→Native)和 upcall(Native→Java)能力
- 查找符号
SymbolLookup 在已加载的库中查找目标函数地址
- 创建 MethodHandle
downcallHandle(地址, FunctionDescriptor) 得到可调用句柄
- 分配参数并调用
Arena 分配堆外内存存放 C 字符串等参数,invoke() 执行
FFM API 的本质是在 JVM 进程内部,通过 MethodHandle 机制直接发起 Native 函数调用。调用路径为 downcallHandle → JVM adapter stub → libffi → 目标 C 函数,完全绕过 java.lang.Runtime 和 java.lang.ProcessBuilder 的代码路径
https://xz.aliyun.com/news/92140
UNIXProcess/ProcessImpl绕过
下面是一个在windows上调用Runtime.exec()的链图,可以发现Runtime.exec()是调用了一整个链子,直到ProcessImpl.create或者UNIXProcess.forkAndExec才脱离JVM的范畴执行native方法
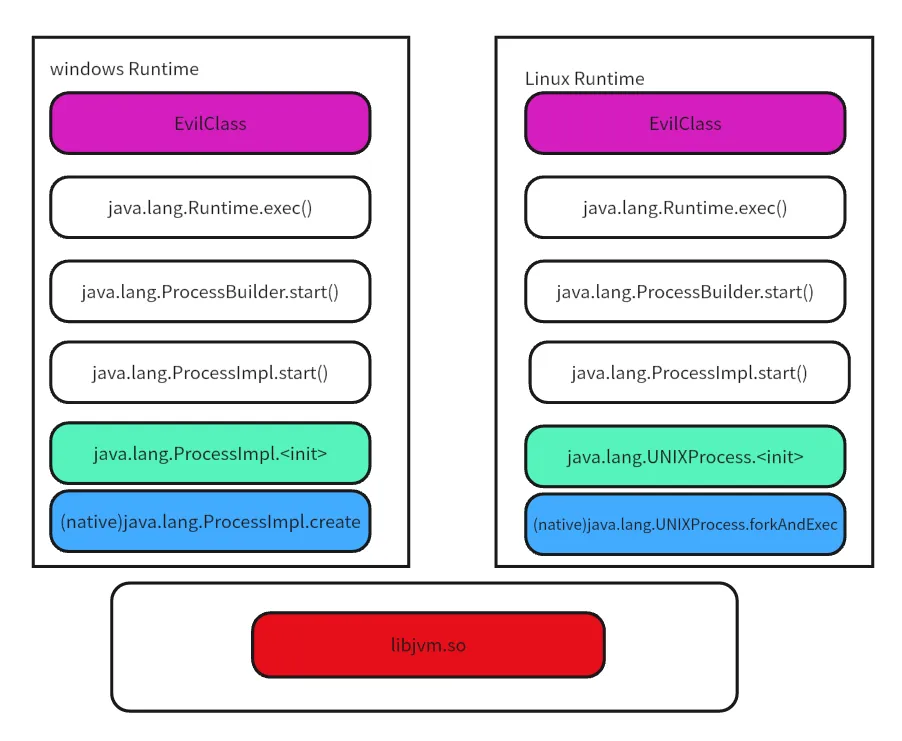
而一些RASP过滤不严,只是单纯地过滤到了 ProcessImpl.start() 或者之前
那么可以直接反射调用 start() 后面的方法进行绕过
古早方法,现在连 forkAndExec 都能 hook 了,所以不多说了
寻找难以覆盖的 hook 点
Java 提供了多种输入输出流的类和接口,目的是为了适应不同的输入输出需求和数据类型场景,根据需求可以大致的分类出以下情况:
- 数据类型差异:字节流(Byte Stream)和字符流(Character Stream)
- 性能优化:缓冲输入输出流(如 BufferedInputStream 和 BufferedOutputStream)
- 数据去向:文件、网络套接字、内存、管道
- 标准化和扩展:Java 支持扩展性,允许开发人员创建自定义的输入输出流来满足特定需求
比如我们链子中用 InputStreamReader 读取文件,未经处理直接 hook 的话在应用运行时将产生大量的误报,这是在生产环境中不可接受的误拦截。比如 Tomcat 等中间件在创建页面时就用到的 InputStream 执行类似的读写操作
输入输出流的难处理,给了我们很大的操作空间,比如 CharArrayWriter 这个类,我们看到将文件路径 path 和内容 context 都通过 java.io.Writer 的实现类进行封装,然后对这两个流进行操作,这种情况下会发生多重引用的问题,如果没有特殊处理就会丢失文件内容。
构造上下文堆栈中难以处理的代码
以 Tomcat 环境下注入 Listener 内存马为例,大多数demo都直接用的 org.apache.catalina.core.StandardContext#addApplicationEventListener() 方法添加恶意对象,实际上可以通过反射获取 applicationEventListenersList 数组添加恶意对象。这时候我们调用的 List.add() 就是再正常不过的操作,并且集合操作广泛存在于应用中,通常不会作为 hook 点存在,因此规避算法
当然内存马不是一个单独存在的漏洞,需要配合反序列化、远程加载等漏洞,并且如果只是最基本的执行命令的内存马同样会被检测,可以用代理内存马,寻求内网突破或者配合第三点中介绍的的写入文件